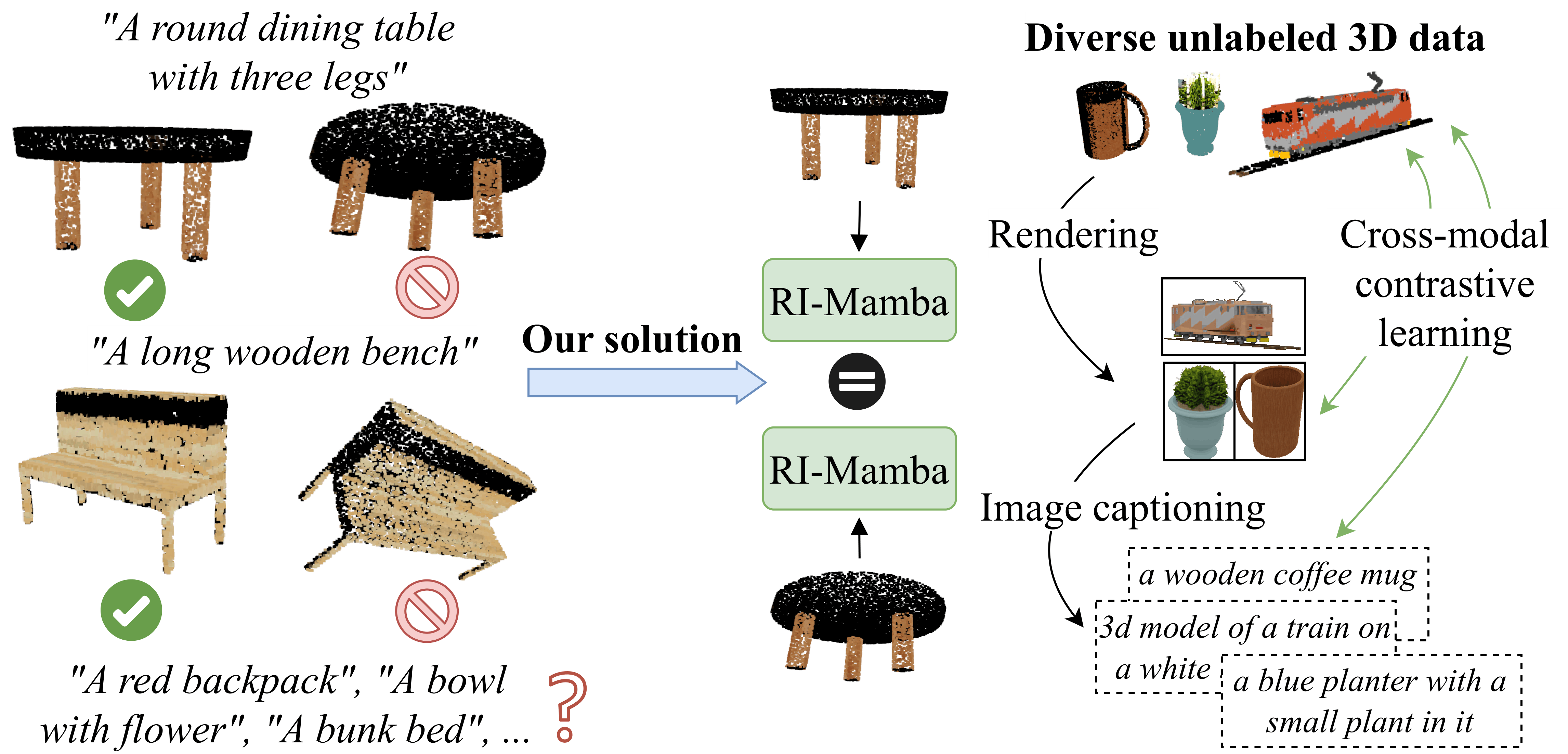
3D assets have rapidly expanded in quantity and diversity due to the growing popularity of virtual reality and gaming. As a result, text-to-shape retrieval has become essential in facilitating intuitive search within large repositories. However, existing methods require canonical poses and support few object categories, limiting their real-world applicability where objects can belong to diverse classes and appear in random orientations. To address this challenge, we propose RI-Mamba, the first rotation-invariant state-space model for point clouds. RI-Mamba defines global and local reference frames to disentangle pose from geometry and uses Hilbert sorting to construct token sequences with meaningful geometric structure while maintaining rotation invariance. We further introduce a novel strategy to compute orientational embeddings and reintegrate them via feature-wise linear modulation, effectively recovering spatial context and enhancing model expressiveness. Our strategy is inherently compatible with state-space models and operates in linear time. To scale up retrieval, we adopt cross-modal contrastive learning with automated triplet generation, allowing training on diverse datasets without manual annotation. Extensive experiments demonstrate RI-Mamba's superior representational capacity and robustness, achieving state-of-the-art performance on the OmniObject3D benchmark across more than 200 object categories under arbitrary orientations.
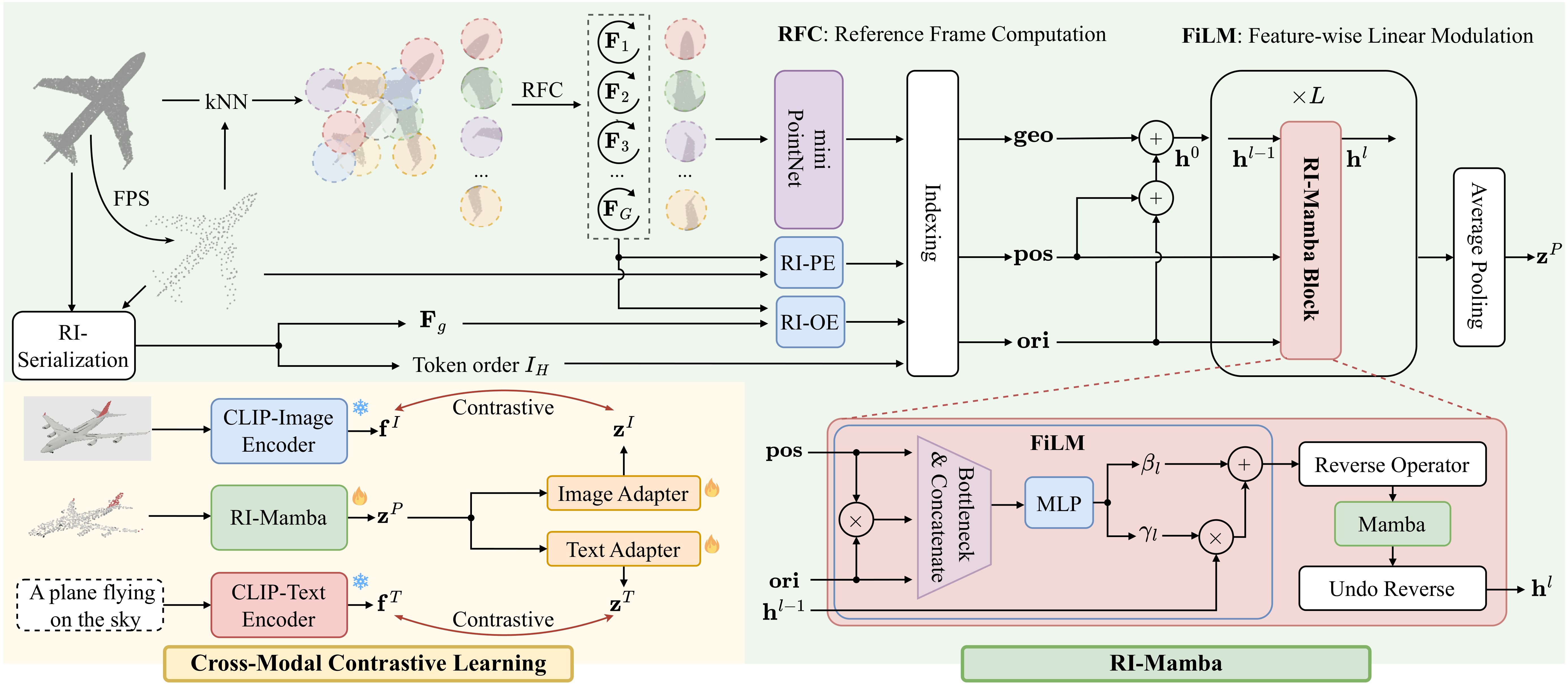
RI-Mamba ensures rotation-invariance and linear complexity through: (1) computing a Global Reference Frame (GRF) and Local Reference Frames (LRFs) via PCA to disentangle object pose from geometric content; (2) leveraging the GRF together with Hilbert sorting to maintain a consistent token ordering under arbitrary rotations while preserving geometric locality; and (3) introducing linear patchwise orientational embeddings derived from the relative poses between the GRF and LRFs.
The RI-Mamba block integrates positional and orientational cues into geometric features using Feature-wise Linear Modulation (FiLM), and enhances contextual information flow and robustness through bidirectional scanning.
For cross-modal contrastive training, RI-Mamba features are aligned with pretrained CLIP image and text embeddings by optimizing the total InfoNCE objective: L = LP→T + LP↔I, where P, I, T denote point cloud, image, and text modalities.
@inproceedings{nguyen2026rimamba,
title={RI-Mamba: Rotation-Invariant Mamba for Robust Text-to-Shape Retrieval},
author={Nguyen, Khanh and Edirimuni, Dasith de Silva and Hassan, Ghulam Mubashar and Mian, Ajmal},
booktitle={CVPR},
year={2026}
}